

22·
7 days agoBiden’s policies brought “the economy” out of it better, at the expense of your average person.
Biden’s policies brought “the economy” out of it better, at the expense of your average person.
There was no “tax the rich” candidate this election. Failing that, people voted for change.
If things didn’t suck for so many people, they would’ve been casting seeds onto stone. It’s much, much harder to radicalize someone that’s content. Instead, the messages found fertile ground. The solution isn’t to just ignore the issue and say “actually everything’s fine, look at numbers go up!”. It’s to give people hope that you’re actually fixing the issue.
It didn’t peter out, it got co-opted and suppressed until Trump capitalized on it. This is that exact same sentiment. People can’t afford groceries and housing, that was a huge issue during the election, so yeah we’ve finally reached a breaking point where people are pissed off about inequality and showed it. Anybody still pushing neolib shit is either braindead or benefits from neofeudalism.
If you’re just some dude, and you’ve got youtubers saying “you matter and you’re cool” on the one hand, and “cis white men suck #KillAllMen”, what do you think you’d be attracted to? That’s a generalization of course, but identity politics has got to go. We need more of this aesthetic on the left:

Not that exact poster obviously, but we need something that gives people a vision of the future and makes it cool. Until that happens, get ready for more Trump and his ilk.
He will bring lots of change. None of it good, but the DNC should view that as a crushing repudiation of their approach. They can’t even blame the Electoral College, they fucked up that badly. Hopefully they’ll learn a goddamn thing or two and run someone offering positive change.
It’s not really about that short of a timeframe. Here’s another example:
https://apps.urban.org/features/wealth-inequality-charts/
Compare 1963 to 2022:
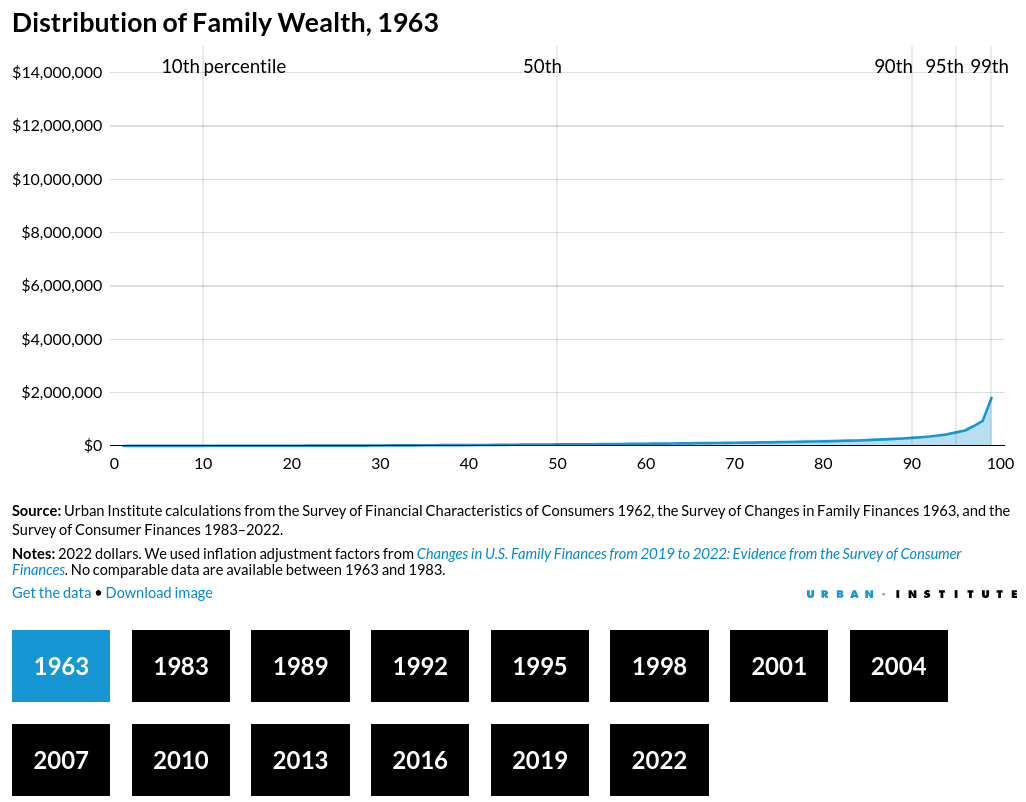
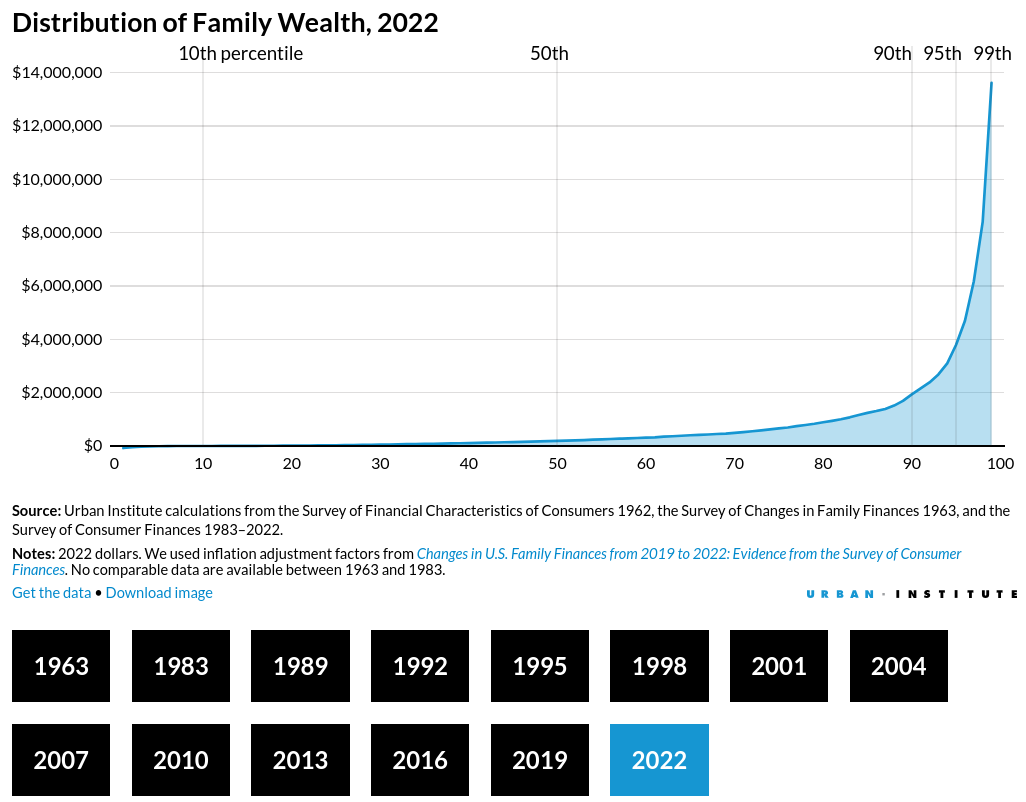
We’re living in a new Gilded Age, people know they’re getting fucked, and saying “Oh, but look at this number going up” doesn’t work anymore.
It doesn’t matter how well “the economy” recovered from Covid, when you see stuff like this:
https://inequality.org/facts/income-inequality/
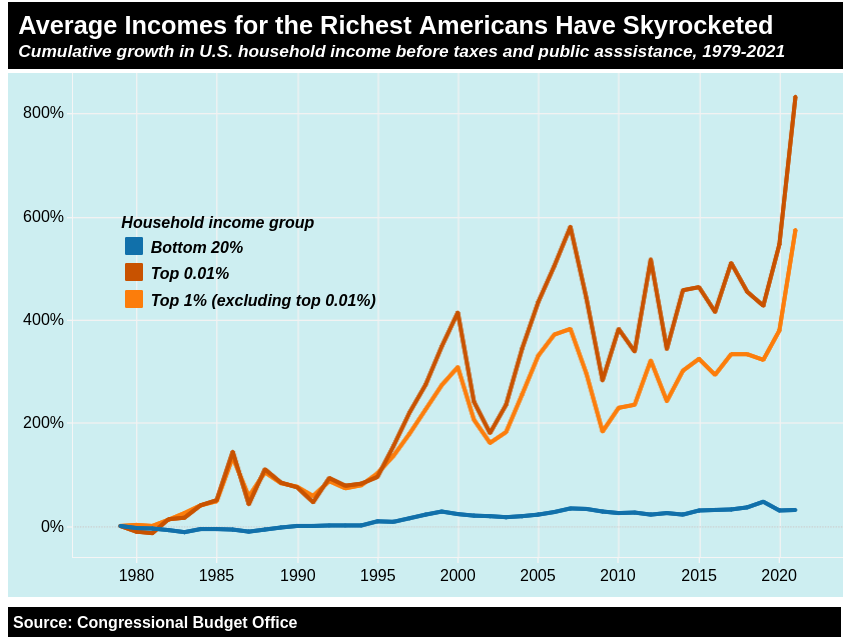
Trump isn’t going to fix that, but Biden already didn’t, and FPTP means you get your pick of those two options.
IMO that’s way off base. People want change. They know they’re getting screwed, and the grifter is promising change. He’s lying and I think most people know that, but the fact that they’d take a convicted felon over what the DNC offered up is a crushing repudiation.
Bernie would’ve mopped the floor with Trump, because he also offers change. Someone like Obama would’ve too, even though there was a paucity of actual change during his terms.
We need to drag the DNC kicking and screaming off of the corporate dick it’s sucking, and get it left enough to offer real change, and people will vote for it in droves.

If he formed a new party with young, fresh faces, I’d vote for them regardless of how that affected whatever the DNC did. I feel like there’s enough similar sentiment that he could force change in the DNC
You’ll like this poem:
https://ncf.idallen.com/english.html
The start of it:
Gerard Nolst Trenité - The Chaos (1922)
Dearest creature in creation Studying English pronunciation, I will teach you in my verse Sounds like corpse, corps, horse and worse.
I will keep you, Susy, busy, Make your head with heat grow dizzy; Tear in eye, your dress you’ll tear; Queer, fair seer, hear my prayer.

The whole “it’s just autocomplete” is just a comforting mantra. A sufficiently advanced autocomplete is indistinguishable from intelligence. LLMs provably have a world model, just like humans do. They build that model by experiencing the universe via the medium of human-generated text, which is much more limited than human sensory input, but has allowed for some very surprising behavior already.
We’re not seeing diminishing returns yet, and in fact we’re going to see some interesting stuff happen as we start hooking up sensors and cameras as direct input, instead of these models building their world model indirectly through purely text. Let’s see what happens in 5 years or so before saying that there’s any diminishing returns.
Gary Marcus should be disregarded because he’s emotionally invested in The Bitter Lesson being wrong. He really wants LLMs to not be as good as they already are. He’ll find some interesting research about “here’s a limitation that we found” and turn that into “LLMS BTFO IT’S SO OVER”.
The research is interesting for helping improve LLMs, but that’s the extent of it. I would not be worried about the limitations the paper found for a number of reasons:
o1-mini and llama3-8B, which are much smaller models with much more limited capabilities. GPT-4o got the problem correct when I tested it, without any special prompting techniques or anything)Until we hit a wall and really can’t find a way around it for several years, this sort of research falls into the “huh, interesting” territory for anybody that isn’t a researcher.
Gary Marcus is an AI crank and should be disregarded
Yeah, it’s not impossible, but it’s much harder and you get a lot less info. You can also counteract the JS-less tracking with Firefox’s privacy.resistFingerprinting, or by using the Tor Browser, which enables a lot of anti-surveillance measures by default. Here’s also another good site for discovering how trackable you are: https://coveryourtracks.eff.org/
They’re also working with browser developers to push htmx into web standards, so that hopefully soon you won’t even need htmx/JS/etc, it’ll just be what your browser does by default
A lot of the web is powered by JS, but much less of it needs to be. Here’s a couple of sites that are part of a trend to not unnecessarily introduce it:
The negative implications for Google requiring JS is that they will use it to track everything possible about you that they can, even down to how you move your cursor, or how much battery you have left on your phone in order to jack up prices, or any other number of shitty things.
Could very well be a mobile thing. I was pretty annoyed recently when logging into gcal for work on my phone, it refused to let me sign in without giving them my cell phone number. When I switched to wifi, it stopped bugging me, so clearly they pay attention to that sort of signal.
Sometimes, yeah. My default is DDG, and I also use Kagi, but Google is still good at some stuff. Guess I’ll take the hit and just stop using it completely though. Kagi has been good enough, and also lets me search the fediverse for finding that dank meme I saw last week. Google used to be able to do that, but can’t shove as many ads in those queries I assume, so they dropped that ability.
{kind=link}
{kind=link}
Because they understand just as well as we do that the way our voting system is set up means you have two options, and anything else is throwing your vote away.
Harris offered a few progressive scraps and then proudly showed off endorsements from the fucking Cheneys. People wanted real change. They’re going to get it, for better or for worse.